Platform
[Cron] Job Monitoring
Cronitor's job monitoring provides complete visibility into your scheduled tasks, cron jobs, and background processes. Track executions, catch failures early, and get alerted when jobs don't run as expected.
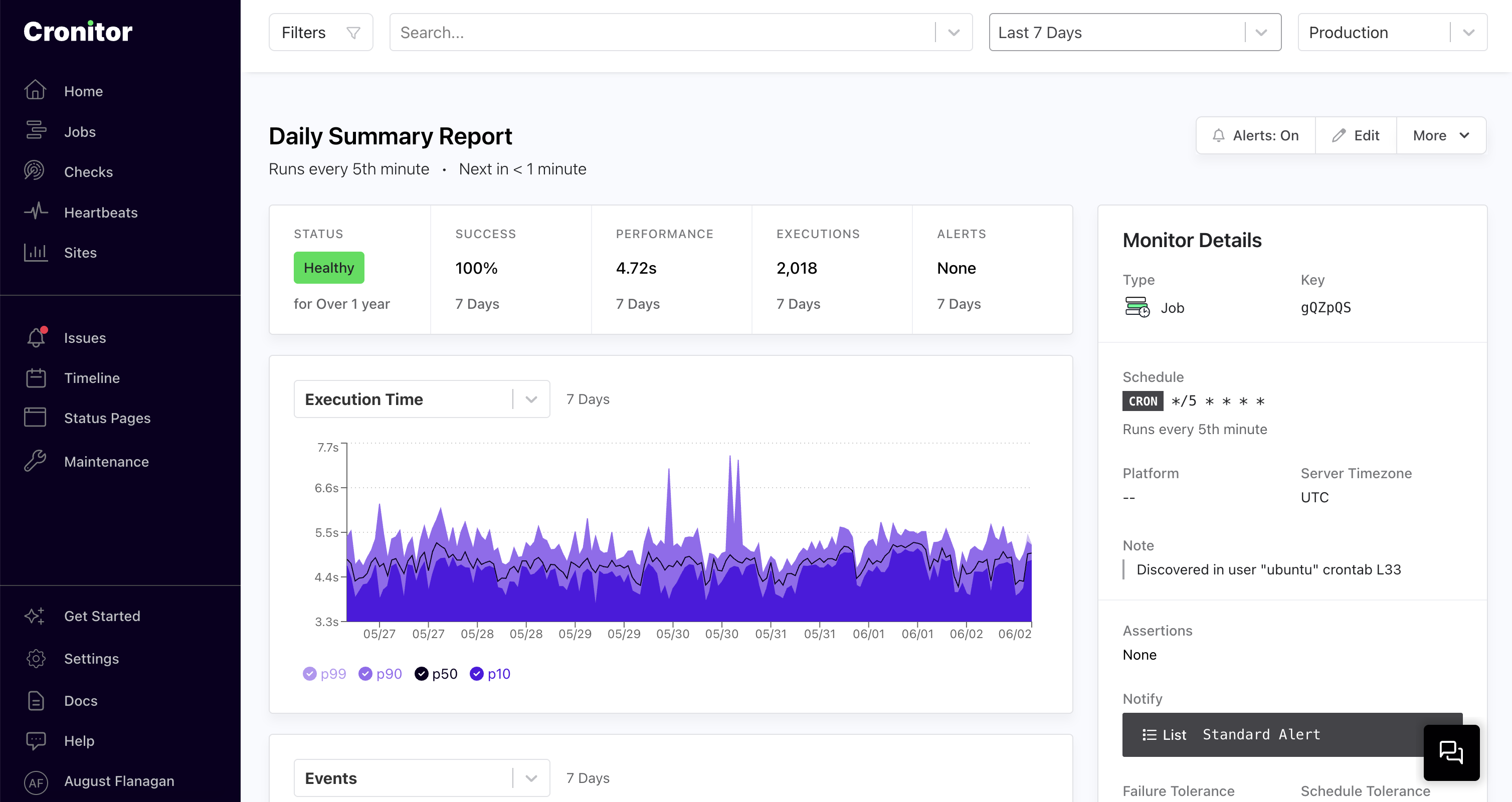
Monitor any type of cron job or background process.
How Job Monitoring Works
Job monitoring tracks the lifecycle of your background tasks using a simple three-event state machine:
| Event Type | Description | Telemetry API Call |
|---|---|---|
| ▶️ Run Event | When your job starts: | curl https://cronitor.link/p/API_KEY/example-cron-job?state=run |
| ✅ Complete Event | When it completes successfully: | curl https://cronitor.link/p/API_KEY/example-cron-job?state=complete |
| ❌ Fail Event | If the job fails/exits with an error code: | curl https://cronitor.link/p/API_KEY/example-cron-job?state=fail |
Platform Integrations
Cronitor provides specialized integrations that automatically discover and monitor existing jobs across many popular background job platforms. These integrations require minimal configuration and provide instant visibility into jobs you may have forgotten about.
- Platform Integrations - Auto-discover jobs on Linux, Kubernetes, Windows, GitHub Actions, Airflow and more
- Language SDKs - Python, Node.js, Ruby, PHP, and more
- Telemetry API - Direct HTTP integration for maximum flexibility
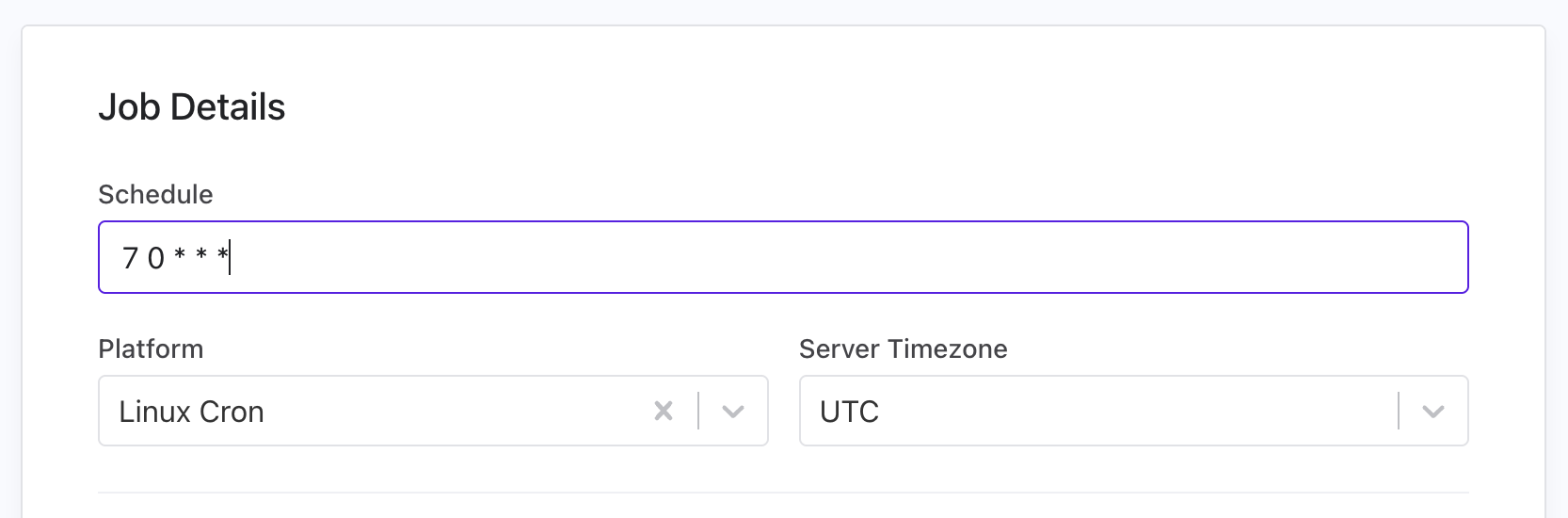
Schedule Configuration
Most background jobs run on an expected schedule/interval. By providing this information to Cronitor you will be alerted when your job does not run according to schedule. You can define when your job should run using cron syntax, interval syntax, or time-of-day expressions:
| Schedule Format | Example | Description |
|---|---|---|
| Cron syntax | "0 2 * * *" | Every day at 2:00 AM |
| Interval syntax | "every 2 hours" | Repeats every 2 hours |
| Time of day syntax | "at 13:37" | Daily at 1:37 PM |
Schedule configuration UI
Monitor API
curl -X PUT "https://cronitor.io/api/monitors" \
-u API_KEY: \
-H "Content-Type: application/json" \
-d '{
"key": "daily-backup",
"type": "job",
"schedule": "7 0 * * *",
"timezone": "UTC" # defaults to account setting
}'
Tolerances & Grace Periods
Make your monitoring more flexible and reduce false alerts by configuring how forgiving Cronitor should be. These settings work together to prevent alert fatigue from jobs that occasionally fail due to external dependencies, network issues, or system load.
| Tolerance Type | Description |
|---|---|
| Failure Tolerance | Allow consecutive failures before alerting |
| Schedule Tolerance | Allow missed scheduled runs before alerting |
| Grace Period | Allow jobs to start late without triggering alerts |
| Alert Surge Protection | Automatically pause alerts after consecutive notifications |
Tolerance & Grace Period Settings

Monitor API
# Create monitor with tolerances
curl -X PUT "https://cronitor.io/api/monitors" \
-u API_KEY: \
-H "Content-Type: application/json" \
-d '{
"key": "daily-backup",
"type": "job",
"failure_tolerance": 3,
"schedule_tolerance": 2,
"grace_seconds": 300,
"consecutive_alert_threshold": 10
}'
Performance Assertions
Monitor job duration and set performance thresholds to catch performance regressions and unexpected behavior:
| Assertion Type | Example | Use Case |
|---|---|---|
| Maximum Duration | "metric.duration < 30 minutes" | Catch jobs that hang or run too long |
| Minimum Duration | "metric.duration > 5 seconds" | Detect jobs that exit too quickly (likely failed) |
Performance Assertion Configuration

Monitor API
# Create monitor with performance assertions
curl -X PUT "https://cronitor.io/api/monitors" \
-u API_KEY: \
-H "Content-Type: application/json" \
-d '{
"key": "daily-backup",
"type": "job",
"assertions": [
"metric.duration < 30 minutes",
"metric.duration > 5 seconds"
]
}'
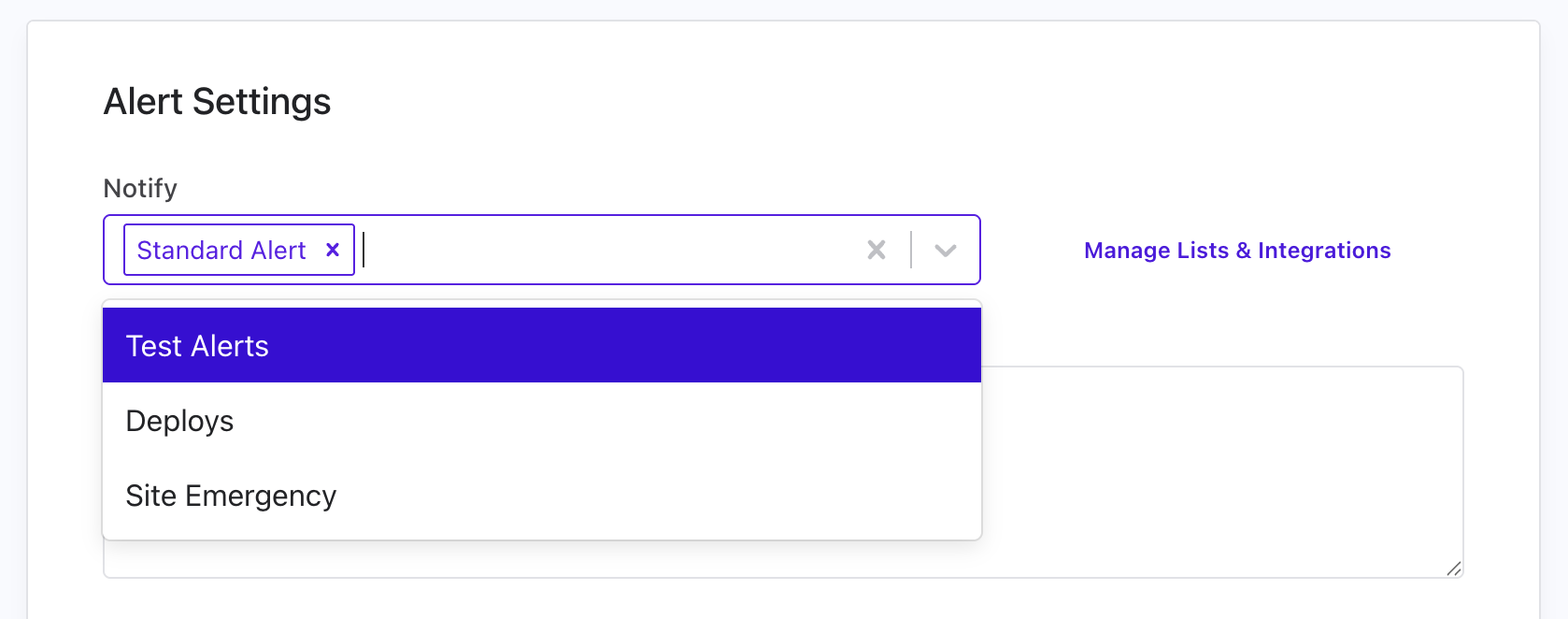
Alert Configuration
When critical jobs fail or miss their schedule, you need to know right away. Cronitor can send alerts to your team through email, Slack, Microsoft Teams, SMS, PagerDuty, webhooks, and more. Setting this up takes just a few steps:
- Create integrations for your preferred services (Slack, Teams, PagerDuty, etc.) in Settings > Integrations
- Create a Notification List with one or more integrations in Settings > Alerts
- Attach your Notification List when creating or updating your job monitor
Issues & Alert Tracking
When your jobs fail or miss their schedule, Cronitor automatically opens an Issue for team coordination and sends alerts to all the configured recipients. Issues give you a persistent record of a failure/outage and can be published to status pages or kept private for internal outage communication. Issues show all sent alerts and timing for complete incident visibility.
Alert & Notification Settings
Monitor API
# Configure alerts using notification lists (recommended)
curl -X PUT "https://cronitor.io/api/monitors" \
-u API_KEY: \
-H "Content-Type: application/json" \
-d '{
"key": "daily-backup",
"type": "job",
"schedule": "7 0 * * *",
"notify": ["on-call-team", "dev-alerts"]
}'
You can also configure alerts directly using formats like email:team@company.com, sms:+15551234567, slack:#alerts, or pagerduty:service-key.
Available Integrations
- Chat Platforms: Slack, Microsoft Teams, Discord
- Incident Management: PagerDuty, OpsGenie, Splunk On-Call
- Direct Notifications: Email addresses, SMS phone numbers
- Custom Integration: Webhooks for any HTTP endpoint
For comprehensive configuration including escalation policies, maintenance windows, and testing your alert setup, see our Alert Documentation.
Environment Support
Separate monitoring data between various environments while sharing monitor configurations:
| Environment Type | Description |
|---|---|
| Staging/Production | Test code in staging before production deployment |
| Multi-Region | Monitor identical jobs across data centers or cloud regions |
# Send to staging environment
curl "https://cronitor.link/p/API_KEY/job-name?state=complete&env=staging"
# Send to production environment
curl "https://cronitor.link/p/API_KEY/job-name?state=complete&env=production"
# Send to specific region
curl "https://cronitor.link/p/API_KEY/job-name?state=complete&env=us-west-2"
Environments are created automatically when you first send a heartbeat with an env parameter. All environments share the same schedule and notification settings, however alerts can be disabled for specific environments. All accounts start with a default production environment.
For detailed environment configuration and management, see our Environment Documentation.